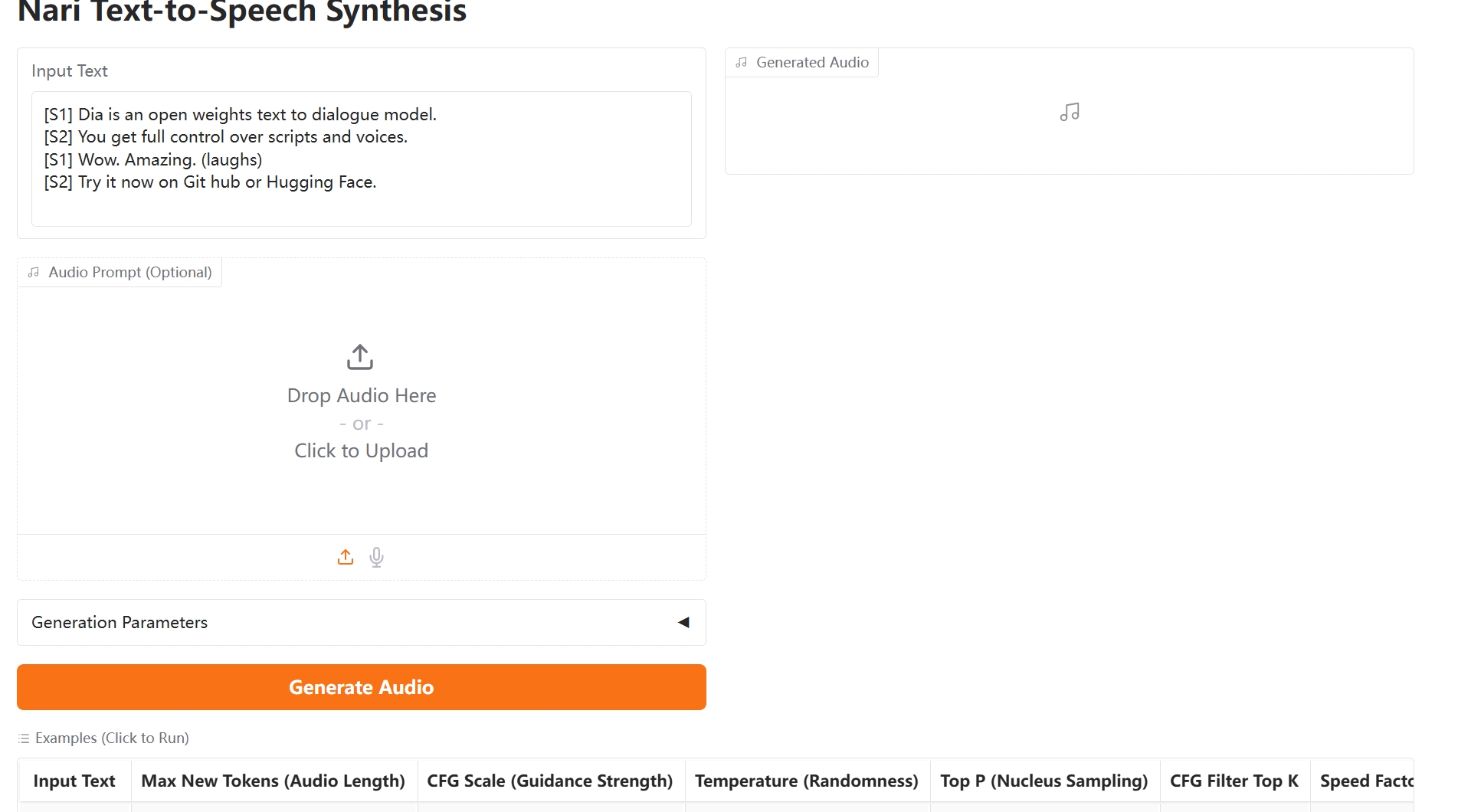
Dia 1.6B TTS ist ein hochmodernes KI-Text-zu-Sprache-Modell, das für ultra-realistische Dialogsynthese entwickelt wurde. Von Nari Labs entwickelt und unter der Apache 2.0 Lizenz veröffentlicht, liefert Dia 1.6B TTS natürliche und ausdrucksstarke Sprachausgabe, die mit kommerziellen Lösungen konkurrieren kann.
- Sprachsynthese mit natürlicher Intonation, Rhythmus und emotionalem Ausdruck durch Dia 1.6B TTS
- Optimiert für die Generierung von Gesprächen mit mehreren Sprechern mit Dia 1.6B TTS
- 1,6B-Parameter-Modell, das mit 10GB VRAM läuft
- Stimmklonfunktionen durch Audio-Prompts